Velvet
About Velvet
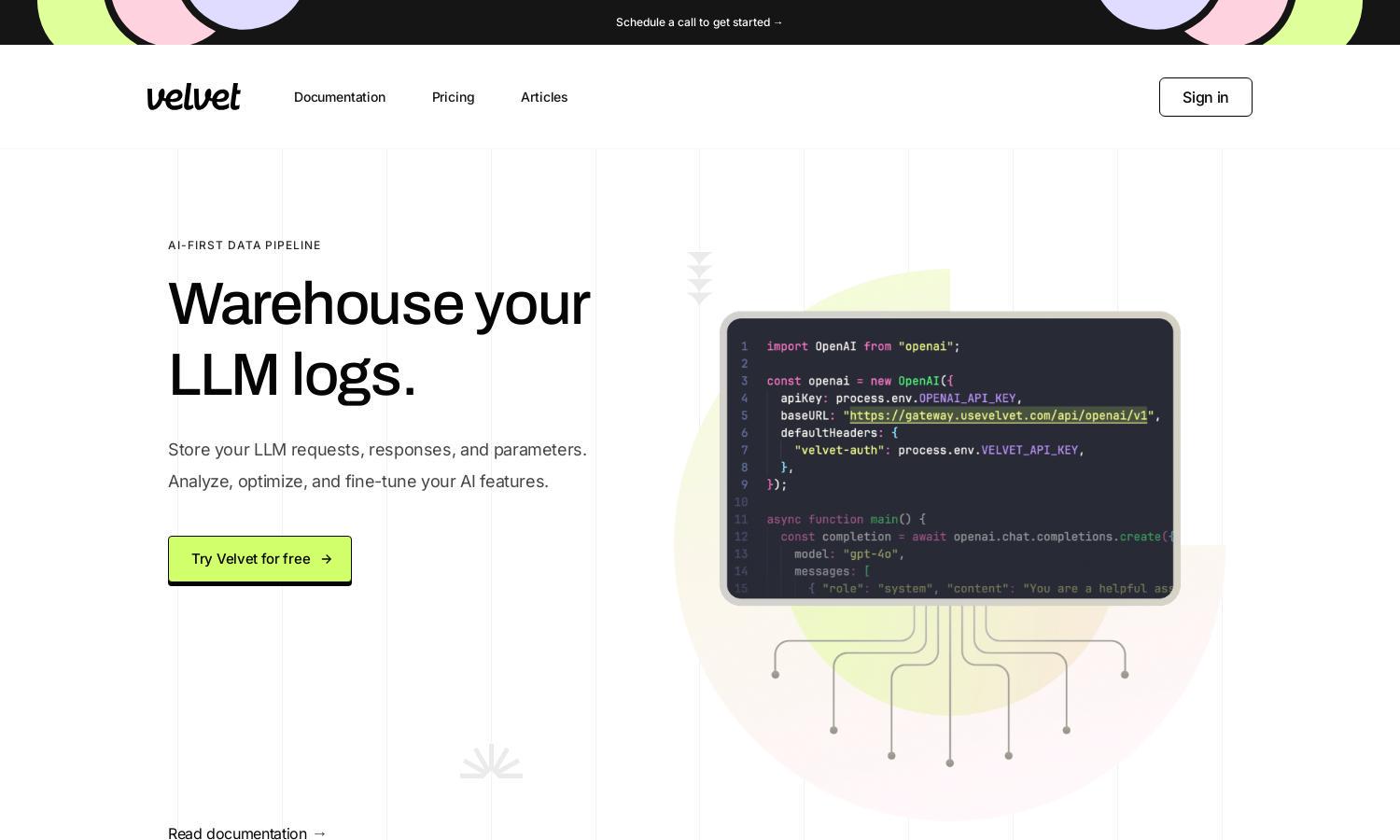
Velvet is an AI gateway designed for engineers looking to optimize their interactions with OpenAI and Anthropic APIs. By logging requests to a PostgreSQL database, users can analyze data, run experiments, and enhance their AI models effortlessly, improving efficiency and insight.
Velvet offers a free plan allowing up to 10,000 requests monthly, ideal for engineers starting out. Users can seamlessly upgrade to paid tiers for enhanced features, such as advanced analytics and customization options, ensuring comprehensive support as their needs grow.
Velvet features a user-friendly interface designed to simplify data logging and analysis. Its intuitive layout helps users navigate easily through various functions like request logging, caching options, and experiment management, providing a seamless experience to optimize AI features effectively.
How Velvet works
Users start by creating an account on Velvet and following onboarding steps that include setting a base URL to the Velvet gateway. They can log requests to their PostgreSQL database using just two lines of code, allowing them to analyze, optimize, and run experiments on AI features efficiently within the platform.
Key Features for Velvet
Log Requests to Database
Velvet's unique feature allows users to log every OpenAI and Anthropic request directly to a PostgreSQL database. This functionality provides engineers with granular visibility into usage patterns and costs, helping them optimize AI training and operational efficiency seamlessly.
Experiment Framework
The Experiment Framework in Velvet enables engineers to run both one-off and continuous experiments on various datasets. This feature allows users to fine-tune AI models and settings efficiently, facilitating a robust approach to optimizing outputs and enhancing AI performance.
Intelligent Caching
Velvet incorporates an intelligent caching system that significantly reduces costs and latency for API calls. This feature enables users to optimize performance by reusing responses for identical requests, ensuring efficient resource utilization and improved response times for AI-driven applications.
You may also like: