Friendli Engine
About Friendli Engine
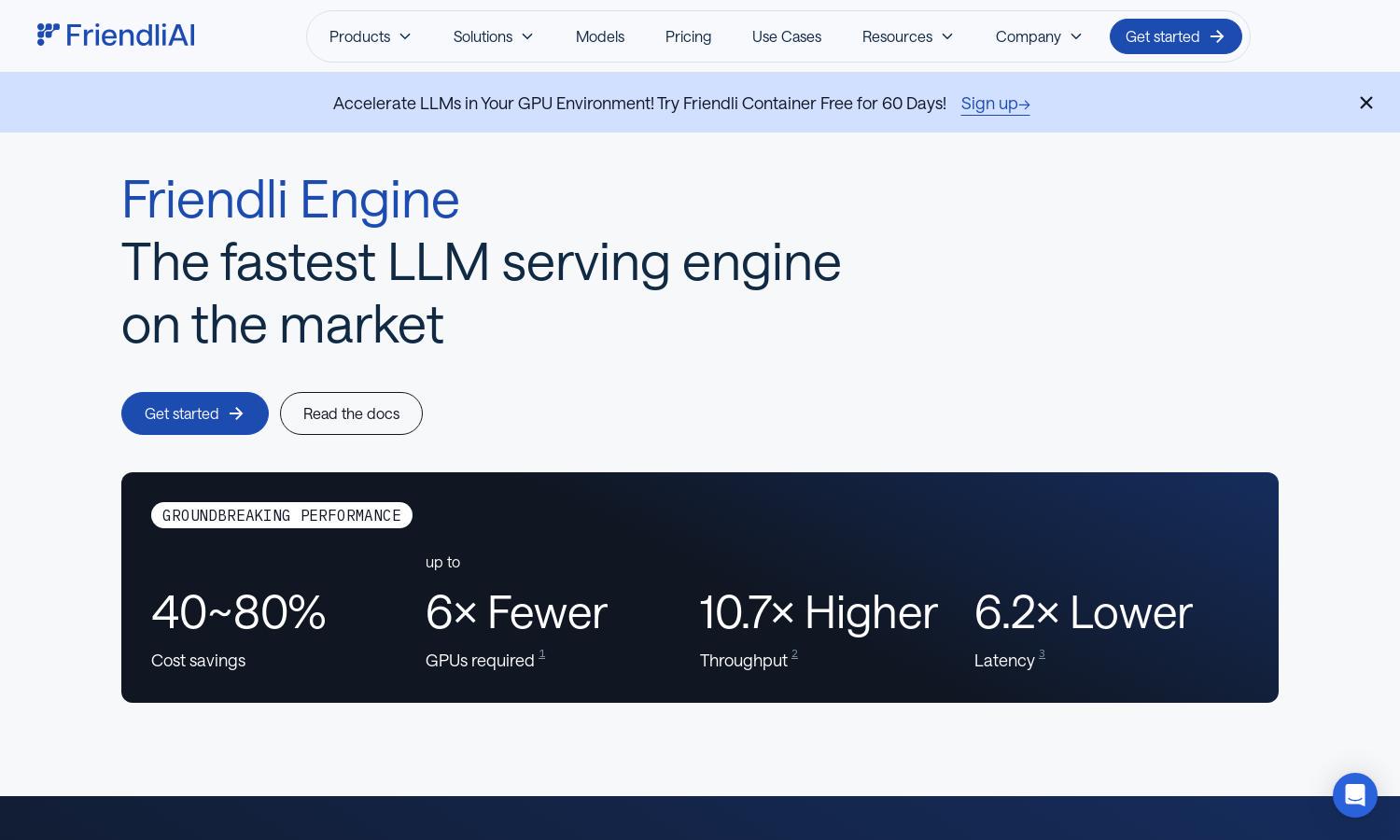
Friendli Engine revolutionizes LLM deployment with optimized performance, allowing users to efficiently serve generative AI models. It supports multi-LoRA serving on a single GPU, significantly reducing costs and enhancing speed. The platform targets developers and businesses eager for rapid, cost-effective AI solutions.
Friendli Engine offers flexible pricing tiers, including free trials for dedicated endpoints and paid plans for advanced features. Each plan provides users with access to high-performance LLM deployment and support. Upgrading unlocks enhanced capabilities, ensuring optimized use of generative AI models, while promoting cost savings.
Friendli Engine features an intuitive user interface designed for seamless navigation. The layout prioritizes ease of access to performance metrics, model management, and deployment strategies. User-friendly elements ensure that both new and experienced users can quickly capitalize on the platform's powerful generative AI capabilities.
How Friendli Engine works
Users begin by signing up for Friendli Engine to access its streamlined interface for generative AI deployment. Upon onboarding, they can select between dedicated endpoints, containers, or serverless options for serving models. The platform's innovative batching and caching technologies ensure optimized performance, making LLM inference both fast and cost-effective.
Key Features for Friendli Engine
Multi-LoRA Serving
Friendli Engine's Multi-LoRA Serving allows simultaneous processing of multiple LoRA models on fewer GPUs. This unique capability streamlines LLM customization, making it accessible and efficient for users. The platform's optimizations significantly reduce resource usage while enhancing inference speed, transforming how generative AI operates.
Iteration Batching Technology
Friendli Engine uses groundbreaking iteration batching technology, greatly increasing throughput for concurrent generation requests. This unique feature provides up to tens of times higher inference rates compared to conventional methods, ensuring that users benefit from rapid response times while meeting their latency requirements.
Friendli TCache
Friendli TCache intelligently stores frequently used computations, enhancing performance by reusing cached results. This efficiency reduces the workload on GPUs, making LLM inference faster and more efficient, thus improving overall user experience and operational costs on Friendli Engine.