Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
Agenta is the open-source platform for teams to build and manage reliable LLM apps together.
Last updated: March 1, 2026
OpenMark AI lets you benchmark 100+ LLMs for cost, speed, quality, and stability on your specific tasks without any setup or API keys.
Last updated: March 26, 2026
Visual Comparison
Agenta
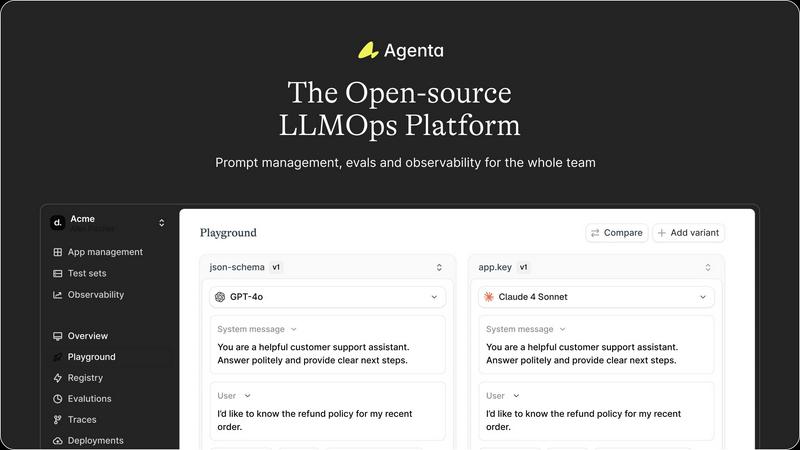
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Prompt Management
Agenta provides a central playground where teams can experiment with, compare, and version-control prompts and models side-by-side in real-time. This creates a single source of truth, ending the chaos of prompts scattered across different tools. You get complete version history for every change, enabling seamless rollbacks and clear audit trails. The platform is model-agnostic, allowing you to integrate and test models from any provider without being locked into a single vendor's ecosystem.
Systematic Evaluation & Testing
Move beyond gut feelings with Agenta's robust evaluation framework. It enables you to create a systematic process for running experiments, tracking results, and validating every change before it ships. You can integrate any evaluator, including LLM-as-a-judge, custom code, or built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and incorporate human feedback from domain experts directly into the evaluation workflow for comprehensive validation.
Production Observability & Debugging
Gain deep visibility into your live LLM applications. Agenta traces every production request, allowing you to pinpoint exact failure points when issues arise. You can annotate traces with your team or gather direct feedback from end-users. A powerful feature lets you turn any problematic trace into a test case with a single click, closing the feedback loop between production and development. Monitor performance and detect regressions automatically with live, online evaluations.
Collaborative Workflow for Teams
Agenta breaks down silos by providing a unified workspace for all stakeholders. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the interface. The platform ensures full parity between its API and UI, allowing both programmatic and manual workflows to integrate seamlessly into one central hub, fostering true collaboration.
OpenMark AI
Simple Task Description
OpenMark AI allows users to define their benchmarking tasks using straightforward, plain language. This feature eliminates the need for technical jargon, making it user-friendly for all team members, regardless of their technical background.
Real-Time Model Comparison
With OpenMark AI, users can test their tasks against over 100 AI models in real-time. This feature provides side-by-side results of actual API calls, ensuring that users are comparing genuine performance metrics instead of outdated or cached data.
Cost Analysis Dashboard
The platform includes a comprehensive cost analysis dashboard that helps users understand the real costs associated with each API call. By analyzing cost efficiency relative to quality, teams can make more informed decisions about which models to implement.
Performance Consistency Checks
OpenMark AI offers features that allow users to assess the consistency of model outputs over multiple runs. This functionality is crucial for teams that need reliable performance in real-world applications, ensuring that the chosen model will deliver consistent results.
Use Cases
Agenta
Accelerating Agent & Chatbot Development
Teams building conversational AI, customer support agents, or complex multi-step AI agents use Agenta to manage the intricate prompt chains and reasoning steps. The unified playground allows for rapid iteration on system prompts and tools, while full-trace evaluation ensures each step in the agent's logic is performing correctly before deployment, leading to more reliable and effective autonomous systems.
Streamlining LLM-Powered Feature Rollouts
When product teams need to integrate LLM features (like content summarization, classification, or generation) into an existing application, Agenta provides the controlled environment to test and evaluate these features. PMs can collaborate with engineers to run A/B tests on different prompts or models, using systematic evaluations to gather evidence on what works best before a full production release.
Managing Enterprise Prompt Portfolios
Large organizations with multiple teams deploying various LLM applications use Agenta as a central governance platform. It prevents duplication of effort and maintains consistency by offering a centralized repository for all prompts and their versions. Subject matter experts across different departments can contribute to and evaluate prompts relevant to their domain within a secure, managed environment.
Debugging and Improving Live AI Systems
When an LLM application in production exhibits unexpected behavior or a drop in performance, engineers use Agenta's observability features to diagnose the issue. By examining detailed traces, they can isolate the failure to a specific prompt, model call, or data input. They can then save the error as a test case, debug it in the playground, and validate the fix through evaluation, ensuring the same error does not reoccur.
OpenMark AI
Model Selection for Product Development
Development teams can utilize OpenMark AI to determine which AI model best fits their product's requirements by benchmarking various models against specific tasks, ensuring optimal performance before deployment.
Cost-Effective AI Implementation
Businesses looking to implement AI features can leverage OpenMark AI to analyze the cost versus quality of different models, allowing them to choose solutions that provide the best return on investment while meeting performance needs.
Research and Development Validation
Research teams can use OpenMark AI to validate their AI models during the R&D phase. By running benchmarks on various models, they can ensure their chosen solution meets the desired criteria before moving forward.
Quality Assurance in AI Outputs
Quality assurance teams can benefit from OpenMark AI by using it to verify the consistency and reliability of model outputs. This ensures that the AI solutions they deploy will perform reliably across different scenarios.
Overview
About Agenta
Agenta is the open-source LLMOps platform designed to transform how AI teams build and ship reliable applications powered by large language models. It directly tackles the core challenge of LLM unpredictability by replacing scattered, chaotic workflows with a centralized, collaborative environment for the entire development lifecycle. Built for cross-functional teams, Agenta brings developers, product managers, and subject matter experts into a single, intuitive workflow. It eliminates the frustration of prompts lost in emails and spreadsheets and debugging that feels like guesswork. The platform's core value lies in seamlessly integrating the three critical pillars of modern LLM development: prompt management, systematic evaluation, and production observability. This unified approach allows teams to experiment rapidly, validate every change with concrete evidence, and efficiently debug issues, dramatically accelerating time-to-production while reducing risk. As an open-source and model-agnostic solution, Agenta provides the flexibility to use any model or framework, preventing vendor lock-in and empowering teams to choose the best tools for their specific application needs.
About OpenMark AI
OpenMark AI is an innovative web application designed specifically for task-level benchmarking of large language models (LLMs). It empowers developers and product teams to evaluate various AI models by allowing users to describe their testing requirements in plain language and execute these prompts across multiple models simultaneously. This capability fosters a comprehensive comparison of key performance metrics such as cost per request, latency, and the scored quality of model outputs, enabling users to visualize the variance in performance rather than relying on potentially misleading singular outputs. Built to assist teams in making informed pre-deployment decisions, OpenMark AI facilitates the selection of the most suitable model for specific workflows while ensuring cost efficiency and output consistency. With a user-friendly interface that does not require API configurations for different model providers, OpenMark AI streamlines the benchmarking process, making it accessible to various teams looking to validate AI features before full deployment.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is fully open-source. You can dive into the code, self-host the platform, and contribute to its development on GitHub. This model provides maximum flexibility, prevents vendor lock-in, and allows teams to customize the platform to fit their specific infrastructure and security requirements.
How does Agenta handle collaboration between technical and non-technical roles?
Agenta is built specifically for cross-functional collaboration. It provides a user-friendly, no-code web interface that allows product managers and domain experts to safely edit prompts, run evaluations, and compare experiment results without writing any code. This bridges the gap between teams, ensuring everyone works from the same centralized data and workflow.
Can I use Agenta with my existing LLM framework and model providers?
Absolutely. Agenta is designed to be model-agnostic and framework-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and can work with models from any provider, including OpenAI, Anthropic, Google, and open-source models from Hugging Face. You bring your own models and APIs.
What is the difference between evaluation and observability in Agenta?
Evaluation in Agenta refers to the systematic testing and scoring of prompts and models during development, typically on curated test datasets, to validate performance before deployment. Observability, on the other hand, is about monitoring the live, production application. It involves tracing real-user requests, debugging issues as they happen, and using that production data to create new tests, closing the loop between live ops and development.
OpenMark AI FAQ
What types of tasks can I benchmark with OpenMark AI?
OpenMark AI supports a wide array of tasks, including classification, translation, data extraction, research, and more. Users can specify their tasks in plain language for tailored benchmarking.
Do I need API keys to use OpenMark AI?
No, OpenMark AI eliminates the need for separate API keys for different models. It uses a credit-based system for hosted benchmarking, simplifying the process for users.
How does OpenMark AI ensure the accuracy of its benchmarks?
OpenMark AI conducts real API calls to various models rather than relying on cached data, ensuring that users receive accurate and up-to-date performance metrics for their benchmarks.
Are there any free trials available?
Yes, OpenMark AI offers a free plan that includes 50 credits for users to explore its features and conduct initial benchmarks without any financial commitment.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed for teams building applications powered by large language models. It centralizes the entire development workflow, from prompt experimentation to evaluation and production monitoring, into a single collaborative environment. Users often explore alternatives for various reasons. Some teams might have specific budget constraints or require a fully managed, cloud-hosted solution. Others might need deeper integrations with their existing tech stack, or their use case might be simpler, focusing on just one aspect like prompt management without the need for a full platform. When evaluating other tools, consider your team's primary need. Look for solutions that address the core challenges of LLM development: managing prompt versions, systematically testing changes, and monitoring live applications. The right fit should streamline your workflow, support collaboration, and provide the observability needed to deploy reliable LLM apps with confidence.
OpenMark AI Alternatives
OpenMark AI is a web application designed for benchmarking large language models (LLMs) at a task level. It allows users to input their testing criteria in plain language, enabling them to run comparisons across multiple models in a single session. This tool is particularly beneficial for developers and product teams who need to validate their choices before integrating AI features into their products. Users often seek alternatives to OpenMark AI for various reasons, such as differences in pricing, specific feature sets, or compatibility with their existing platforms. When searching for an alternative, it’s essential to consider factors like cost efficiency, model diversity, user experience, and the ability to produce consistent results. Finding a tool that aligns with your team's needs can enhance the decision-making process when selecting the right AI model.