Tuning Engines
Tuning Engines is a unified AI runtime that lets you govern, optimize, and deploy any model through one secure API with zero infrastructure markup.
AI tool Details
Explore More
Alternatives
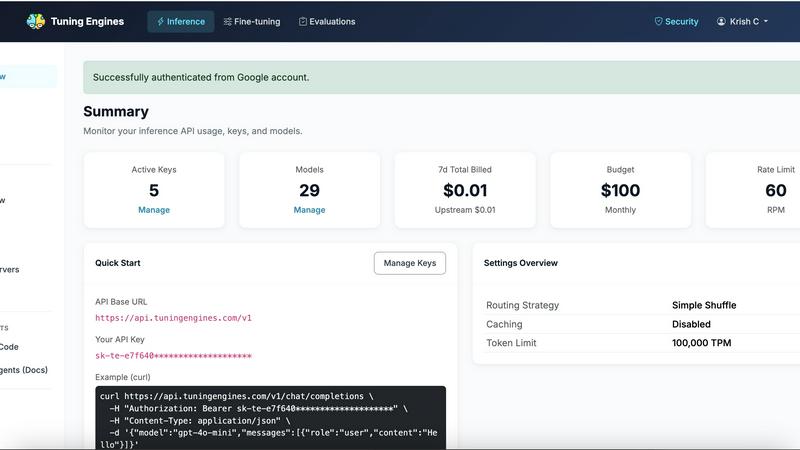
About Tuning Engines
Tuning Engines is a unified AI control and governance layer built for teams that need to move beyond isolated experiments and into production-grade intelligence. It brings together the full AI lifecycle in one governed platform, covering inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, policy-as-code, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. Designed for developers and admins alike, it offers OpenAI-compatible APIs and Anthropic-compatible routes, CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills. Teams can connect popular AI workflows like Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, and Windsurf through a single governed platform. For admins, Tuning Engines provides role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. Its main value proposition is helping organizations secure, govern, and optimize every AI interaction with centralized policy control, auditability, and token economics managed by design. A standout differentiator is that infrastructure costs are passed through at-cost with zero markup, so you only pay for support and platform upkeep.
Features
Unified Inference
Access any model through one OpenAI-compatible endpoint. Keep your existing SDK and simply swap one base URL to call open, frontier, or your own tuned models. This feature supports 100+ models including Llama 3.3, DeepSeek V3, Qwen 2.5, Mistral, Gemma, and more, plus commercial frontier models and any model you fine-tune. Every request gets centralized policy, full auditability, and token controls applied automatically. Streaming and structured output are supported out of the box, making the transition from prompt to production seamless without rewriting your stack.
Model Tuning and Lifecycle
Adapt open models to your data, workflows, and production goals with supervised fine-tuning and LoRA adapters. Tuning Engines handles the entire model lifecycle from build to tune to scale. You can run supervised fine-tuning jobs, manage datasets, and set evaluation gates so quality moves with your business. Once tuned, your custom models are available through the same unified API endpoint alongside open and commercial models. This eliminates the need to manage GPU infrastructure separately and lets you iterate quickly on model improvements.
Policy and Governance Controls
Admins get comprehensive controls for production environments including role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, and policy-as-code with AGT YAML. Every request is traceable with runtime traces and usage analytics, providing full auditability across all models, agents, and tools. Credential sources, tenant isolation, and team management ensure that different projects or clients stay securely separated. Token economics features like cost ceilings, quotas, and routing keep spend and rate limits predictable.
Model Library and Resource Catalog
Instant access to popular open-weight models like Llama 3.3 70B, DeepSeek R1, Qwen 2.5 Coder 32B, Mistral Small 3, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and Embeddings from the BGE and E5 families. All models are available through one OpenAI-compatible API with a single line of code. The resource catalog also includes agents, tools, and skills that can be reused across projects. This makes it easy to experiment with different models and quickly switch between them without changing your application code.
Use Cases
Code Assistance
Build IDE copilots, code generation tools, refactoring assistants, and debugging agents that connect through a single governed platform. Teams can integrate with popular coding tools like Cursor, VS Code, Windsurf, Continue.dev, and Claude Code, ensuring all AI-assisted development happens under centralized policy control, auditability, and token economics. Developers get the speed of direct model access while admins maintain visibility and cost controls across every coding interaction.
Conversational AI
Deploy customer support bots, internal helpdesks, and multilingual chat applications that leverage multiple models through one API. Use routing profiles and fallback policies to ensure high availability and consistent quality. Guardrails and policy-as-code keep conversations safe and compliant, while usage analytics help optimize costs and performance. The unified endpoint means you can swap models or add new ones without touching your chat application code.
Agentic Systems
Build multi-step reasoning, planning, and tool-using execution pipelines that combine models, agents, MCP servers, and reusable skills. Tuning Engines provides the governance layer for agentic workflows, ensuring each step is traceable, auditable, and within budget. Agents can automatically route between different models based on task complexity, use fallback models if primary ones fail, and stay within defined cost ceilings and rate limits.
Enterprise RAG
Implement secure, scalable retrieval augmented generation over knowledge bases and private documents. Use embedding models from the library alongside LLMs for generation, all through the same unified API. Policy controls ensure that sensitive data stays protected, while tenant isolation keeps different departments or clients separate. The platform supports multimodal inputs including text, vision, and speech, making it suitable for complex enterprise search and recommendation systems.
Frequently Asked Questions
How does Tuning Engines handle pricing and infrastructure costs?
Infrastructure costs for model inference are passed through at-cost with zero markup. You only pay Tuning Engines for support and platform upkeep. This means you get access to a wide range of open and commercial models without paying inflated margins on compute. Token economics features like cost ceilings, quotas, and routing profiles help keep spend predictable and within budget.
Can I use my existing OpenAI SDK with Tuning Engines?
Yes. Tuning Engines provides an OpenAI-compatible endpoint at https://api.tuningengines.com/v1/. You keep your existing SDK and simply change the base URL and API key. No code rewrites or new client libraries are needed. The endpoint supports all standard OpenAI parameters including streaming, structured output, and function calling.
What models are available through the platform?
The model library includes popular open-weight models like Llama 3.3 70B, DeepSeek V3 and R1, Qwen 2.5 72B, Mistral Small 3, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and embedding models. Commercial frontier models are also accessible, plus any model you fine-tune with Tuning Engines. All models are available through the same unified API.
How does Tuning Engines ensure security and compliance?
The platform provides role-based access control, per-key budgets and rate limits, routing profiles with fallback rules, guardrails, and policy-as-code using AGT YAML. Every request is fully traceable with runtime traces and usage analytics. Credential sources, tenant isolation, and team management ensure that different projects and users stay securely separated. All controls are centralized and auditable.
Similar to Tuning Engines
Distro
AI distribution operator for content, conversations, outreach, and pipeline.
Polymarket Trading Bot For Crypto
Polymarket Trading Bot For Crypto
HyperLake
HyperLake is your command center for deploying sovereign AI agent infrastructure in your cloud with zero compute markup and governed access.
Minded
Record once to train AI agents that clear tasks off your plate in minutes, all managed in plain English.

Klaws
Klaws is an AI agent that works 24/7, learns anything, and ships real tasks like research, emails, and code while you sleep.

Playwriter
Playwriter lets your agents control Chrome seamlessly with AI, utilizing existing sessions and full Playwright API without bot detection.

Patrivox
Patrivox transforms your archives into fully searchable documents in minutes, making knowledge accessible and organized.

Stable Commerce
Launch your online store in under 2 minutes with our AI managing setup, optimization, and everything in between.